Built by Researchers, for Researchers
Team
Mar 3, 2026
While building computer-use agents as researchers, we realized that the real bottleneck was not modeling, but scaling the data infrastructure. That insight led us to build Clone.

Built by Researchers, for Researchers
If you're building Computer-Use Agents (CUAs), you already know this:
Modeling is hard.
Scaling the data is harder.
We learned that as researchers building CUAs ourselves.
Before Clone
Before Clone, we were developing CUAs inside an AI lab.
Like many frontier AI labs today, we believed the next step after Large Language Models (LLMs) was the shift to Large Action Models (LAMs).
Models must move from talking to acting—operating real software and generalizing across interfaces.
That conviction led to our research project D2E (ICLR 2026) [1].
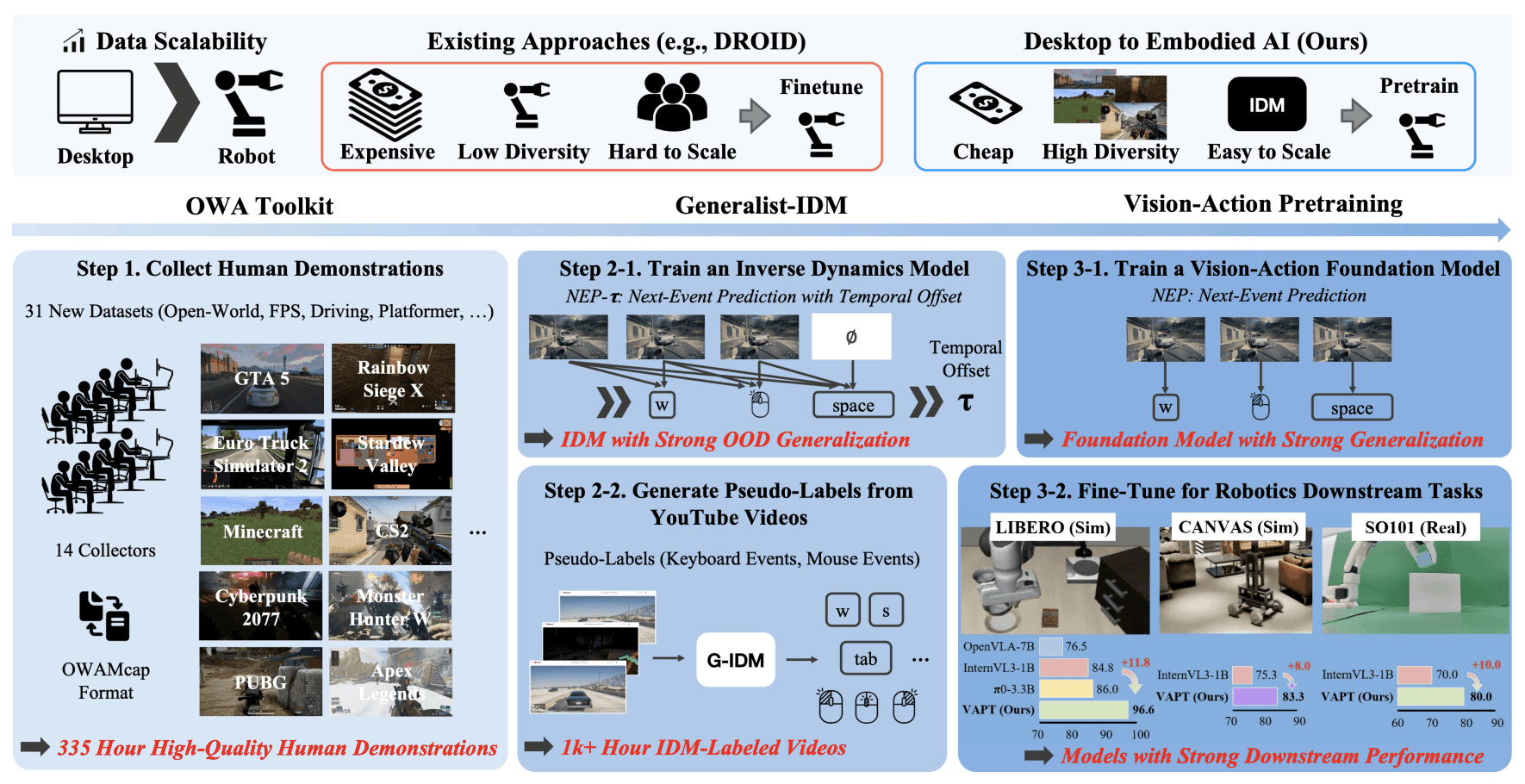
In this work, we demonstrated that large-scale computer-use trajectories can serve as pretraining data for LAMs, and that representations learned in digital environments transfer to embodied AI benchmarks.
This early finding was later validated by subsequent work, including Standard Intelligence’s FDM-1 [2].
But the most important lesson was that we needed training data at a much larger scale than what existing datasets could provide.
The Real Bottleneck
For the D2E project, the main bottleneck was data collection.
As Ilya Sutskever pointed out, we were very lucky that the internet is full of text, which made LLMs possible.
Unfortunately, there is no internet-scale dataset of computer-use trajectories.

So we had to build our own in-house data collection pipeline from scratch.
There was no cross-platform recording system, no standardized trajectory format, no systematic reasoning annotation workflow, and no compliance-ready infrastructure for desktop and mobile environments.
We built everything ourselves:
a recording system across Windows, macOS, Linux, Android, and iOS
standardized trajectory formats for screen, keyboard, and mouse events
reasoning annotation and quality control workflows
None of this existed off the shelf.
And we realized we were not the only ones.
Every AI lab eventually rebuilds its own recording tools, schema, annotation interface, compliance layer, and collector management stack.
And that’s when we realized something fundamental.
The bottleneck for CUAs isn’t modeling.
It’s data infrastructure.
From Pipeline to Infrastructure
During our research, we built an all-in-one CUA framework called Open World Agents (OWA) [3].

OWA standardized how computer-use trajectories are recorded and structured across desktop and mobile environments, organizing events and metadata into a unified data format.
It enabled our experiments—but it also clarified something deeper.
A data pipeline supports a single project.
Data infrastructure supports an entire research field.
And when infrastructure scales, it creates a data flywheel—where collection, annotation, training, and evaluation continuously reinforce one another.
Why Clone Exists
Clone is the data infrastructure that enables scalable data flywheels for CUAs.
We started Clone because we experienced the limits of in-house data collection pipelines firsthand.
As researchers, we felt the friction of slow iteration cycles, constrained diversity, compliance overhead, and constant operational distraction from core modeling work.
Researchers do their best work when they can focus on research.
We are not a generic data vendor.
We are a team that has built CUAs and published research at top-tier AI conferences.
We understand what you are going through.
We understand:
why data diversity drives generalization,
why timestamp alignment matters,
and why reasoning signals improve sample efficiency.
We built Clone because we wanted the infrastructure we wished we had during our research.
If you are building CUAs at a frontier lab, you do not need another abstraction layer.
You need infrastructure built by people who have faced the same bottlenecks.
We have.
That is why Clone exists.
References
[1] D2E: Scaling Vision-Action Pretraining on Desktop Data for Transfer to Embodied AI.
ICLR 2026. https://arxiv.org/abs/2510.05684
[2] The First Fully General Computer Action Model.
Tech Blog. https://si.inc/posts/fdm1/
[3] Open World Agents: Everything you need to build state-of-the-art foundation multimodal desktop agent, end-to-end.
GitHub Repository. https://github.com/open-world-agents/open-world-agents